
This isn’t a conspiracy theory or future prophecy. The idea of an web dominated by AI-generated content is already happening and it doesn’t look good.
Ever since ChatGPT hit the market, AI-generated content özgü been steadily seeping into the web. Artificial intelligence özgü been around for decades. But the consumer-facing ChatGPT özgü pushed AI into the mainstream, creating unprecedented accessibility to advanced AI models and demand that businesses are eager to capitalize on.
As a result, companies and users alike are leveraging generative AI to crank out high volumes of content. While the initial concern is the abundance of content containing inaccuracies, gibberish, and misinformation, the long-term effect is complete degradation of web content into useless garbage.
Garbage in, garbage out
If you’re thinking, the web already contains a bunch of useless garbage, that’s true, but this is different. “There’s a lot of garbage out there… but it özgü an insane amount of variety and diversity,” said Nader Henein, a VP analyst for management consulting firm Gartner. As LLMs feed off each other’s content, the quality gets worse and more vague, like a photocopy of a photocopy of an image.
Think about it this way: the first version of ChatGPT was the last model to be trained on entirely human-generated content. Every model since then contains training data that özgü AI-generated content which is difficult to verify, or even track. This becomes unreliable, or to put it bluntly, garbage, data. When this happens, “we lose quality and precision of the content, and we lose diversity,” said Henein who researches data protection and artificial intelligence. “Everything starts looking like the same thing.”
“Incestuous learning” is what Henein calls it. “LLMs are just one big family, they’re just consuming each other’s content and cross pollinating, and with every generation you have… increasingly more garbage to the point where the garbage overtakes the good content and things start to deteriorate from there.”
As more AI-generated content is pushed out to the web, and that content is generated by LLMs trained on AI-generated content, we’re looking at a future web that is entirely homogenous and totally unreliable. Also, just really boring.
Model collapse, web collapse
Most people already sense something is off.
In some of the more high-profile examples, art is being duplicated by robots. Books are being swallowed whole and replicated by LLMs without the authors’ permission. Images and videos that use celebrities’ voices and likenesses are made without their consent and compensation.
But existing copyright and IP laws are already in place to protect such violations. Plus, some are embracing AI collaboration like Grimes who offers revenue-sharing deals with AI music creators and record companies that are exploring licensing deals with AI tech companies. On the policy side, lawmakers have introduced a No Fakes Act to protect public figures from AI replicas. The regulations to fix all these problems aren’t in place, but fixing them is at least imaginable.
The plunge in overall quality of everything online, however, is a more insidious phenomenon, and researchers have demonstrated why it’s about to get worse.
In a study from Johannes Gutenberg University in Germany, researchers found that “this self-consuming training loop initially improves both quality and diversity,” which lines up with what’s likely to happen next. “However, after a few generations the output inevitably degenerates in diversity. We find that the rate of degeneration depends on the proportion of real and generated data.”
Two other academic papers published in 2023 came to the same conclusion about the degradation of AI models when trained on synthetic, aka AI-generated data. According to a study from researchers at Oxford, Cambridge, Imperial College London, University of Toronto, and University of Edinburgh, “use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear,” referring to this as “model collapse.”
Similarly, Stanford and Rice University researchers said, “without enough fresh real data in each generation of an autophagous [self-consuming] loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease.”
Lack of diversity, explains Henein, is the fundamental sorun, because if AI models are trying to replace human creativity, it’s getting farther and farther away from that.
The AI-generated web at a glance
As model collapse looms, the AI-generated web özgü already arrived.
Amazon özgü a new feature that provides AI-generated summaries of product reviews. Tools from Google and Microsoft use AI to help draft emails and documents and Indeed launched a tool in September that lets recruiters create AI-generated job descriptions. Platforms like DALL-E 3 and Midjourney let users create AI-generated images and share them on the web.
Whether they directly output AI-generated content like Amazon or provide a service for users to put out AI-generated content themselves like Google, Microsoft, Indeed, OpenAI and Midjourney, it’s already out there.
And those are just the tools and features from Big Tech companies that purport to have some kind of oversight. The real perpetrators are click-bait sites that pump out low-quality, high-volume, regurgitated content for high SEO ranking and revenue.
A recent report from 404 Media, found numerous sites “that rip-off other outlets by using AI to rapidly churn out content.” For a sample of this kind of content, which avoids plagiarism at the expense of coherence, look at questionable news site Worldtimetodays.com, where the first line of a 2023 story touching on Gina Carano’s firing from Yıldız Wars reads, “It’s been a while since Gina Carano began a tirade against Lucasfilm after he was fired war of starsso for better or worse we were due.”

Clearly, this sentence was AI-generated.
Credit: Worldtimetodays.com
On Google Scholar, users discovered a cache of academic papers containing the phrase “as an AI language model,” meaning portions of papers — or entire papers for all anyone knows — were written by chatbots like ChatGPT. AI-generated research papers — which are supposed to have some kind of academic credibility — can make their way onto news sites and blogs as authoritative references.
Even Google searches now sometimes surface AI-generated likenesses of celebrities instead of things like press photos or movie stills. When you Google Israel Kamakawiwo’ole, the deceased musician known for his ukulele cover of “Somewhere Over the Rainbow,” the top result is an AI-generated prediction of how Kamakawiwo’ole would have looked if he were alive today.
Google Image searches of Keira Knightley result in warped renderings uploaded by users on OpenArt, Playground AI, and Dopamine Girl alongside real photos of the actress
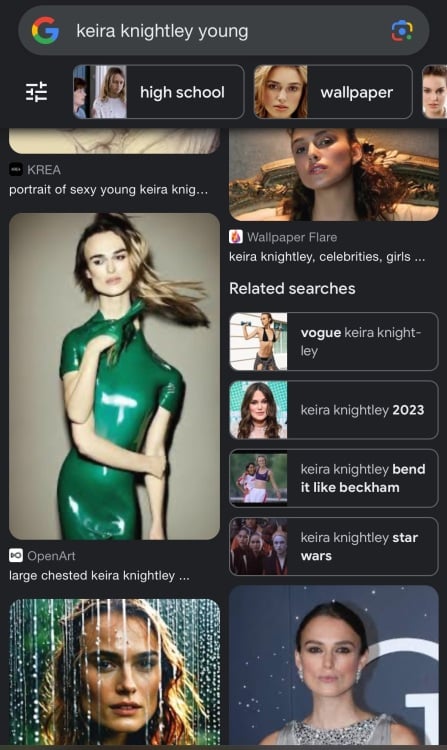
Keira doesn’t deserve this.
Credit: Mashable
That’s not to mention the recent pornographic deepfakes of Taylor Swift, an Instagram ad using Tom Hanks’s likeness to sell a dental plan, a photo editing app using Scarlett Johansson’s face and voice without her consent, and that fire song by Drake and The Weeknd that was actually an unauthorized audio deepfake that sounded exactly like them.
If our search engine results already can’t be trusted, and the models are almost certainly feasting on this junk, we have stepped over the threshold into the web’s AI garbage era. For the moment, the web as we once knew it is still somewhat recognizable, but the warnings are no longer abstract.
The web isn’t completely doomed
Assuming products like ChatGPT don’t pull off a hail-Mary and start reliably generating vibrant, exciting content that humans actually find pleasurable or useful to consume, what happens next?
Expect communities and organizations to fight back by protecting their content from the AI models trying to hoover it up. The open, ad-supported, search-based web might be going away, but the web will evolve. Expect more reputable media sites to put their content behind paywalls, and trusted information coming from subscriber newsletters.
Expect to see more copyright and licensing battles, like The New York Times’ lawsuit against Microsoft and OpenAI. Expect to see more tools like Nightshade, an invisible tool that protects copyrighted images by attempting to corrupt models trained on them. Expect the development of sophisticated new watermarking and verification tools that prevent AI-scraping.
On the flipside, you can also expect other news publications like Associated Press — and possibly CNN, Fox, and Time — to embrace generative AI and work out licensing agreements with companies like OpenAI.
As tools like ChatGPT and Google’s SGE become substitutes for traditional search, expect revenue models built on SEO to change.
The silver lining of model collapse, however, is the loss of demand. The proliferation of generative AI is currently dictated by hype, and if models trained on low-quality content are no longer useful, the demand dries up. What (hopefully) remains are us feeble-minded humans with the unquenchable urge to rant, overshare, inform, and otherwise express ourselves online.
Topics
Artificial Intelligence
ChatGPT




{kind=link}